 Cloud Ops Chronicles
Cloud Ops Chronicles
La quête du Graal Devops : Concilier scaling à zéro et disponibilité immédiate
Dans le monde impitoyable du cloud, chaque ressource inutilisée représente un coût inutile. Le scaling à zéro des pods Kubernetes, bien que séduisant pour optimiser les coûts, se traduit souvent par une expérience utilisateur dégradée avec des applications indisponibles. Comment alors concilier économies et réactivité ?
Oubliez les compromis, et adoptez une approche pilotée par les événements, en combinant la puissance d’Event Driven Ansible à la finesse d’outils tels qu’Istio, Prometheus et Alertmanager. Imaginez un système capable de :
- Détecter instantanément les premiers appels HTTP vers vos applications.
- Déclencher automatiquement le lancement de vos pods Kubernetes pour répondre à la demande.
- Orchestrer la mise à l’échelle de vos ressources de manière dynamique et transparente.
- Réduire vos coûts d’infrastructure en stoppant les pods inactifs.
Plus besoin d’attendre le redémarrage de vos applications, la disponibilité est quasi-immédiate, et vos utilisateurs ne se rendent compte de rien !
Dans cet article, nous allons explorer en détail comment mettre en place cette solution élégante et efficace. Vous découvrirez :
- Les mécanismes de détection d’événements basés sur le trafic HTTP.
- La configuration d’alertes intelligentes pour déclencher l’autoscaling.
- La mise en œuvre de playbooks Ansible pour automatiser le scaling de vos déploiements.
Préparez-vous à dire adieu aux compromis et à entrer dans l’ère du scaling à zéro intelligent !
Comprendre le Problème¶
Considérons un environnement de développement ou de test. Un “opérateur” pourrait allumer l’environnement avant son utilisation et l’éteindre (scaling à zéro) après. Cependant, l’approche DevOps vise à automatiser ces processus pour éliminer les interventions manuelles.
Le défi réside dans la recherche d’une solution automatique pour gérer le scaling de manière dynamique, en s’adaptant aux fluctuations de la demande. Nous voulons que l’environnement soit disponible immédiatement lorsqu’il est nécessaire, sans que les utilisateurs ne subissent de délai d’attente.
La Solution : Autoscaling piloté par les Événements¶
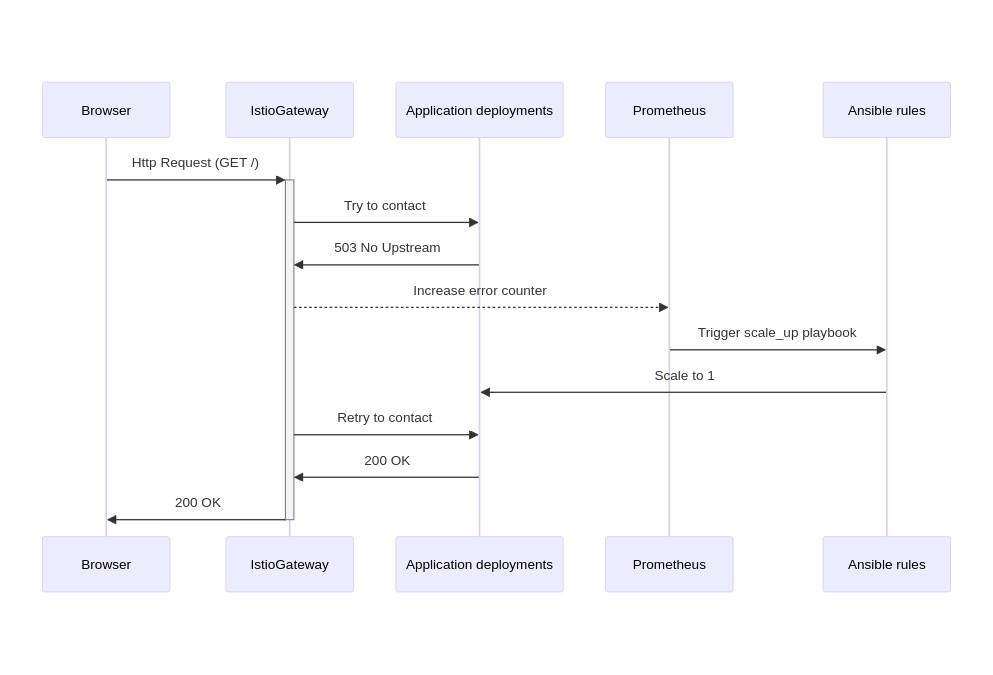
L’autoscaling basé sur les événements est la clé pour concilier économies de ressources et disponibilité immédiate. L’idée est de surveiller le trafic HTTP vers les pods Kubernetes et de déclencher automatiquement le scaling (augmenter le nombre de pods) lorsque les demandes ne trouvent pas de destinations.
Fonctionnement du Système¶
- Détection des Événements: Istio, un outil de gestion de trafic, surveille le trafic HTTP vers vos pods Kubernetes.
- Collecte de Données: Prometheus, un système de monitoring, collecte les données de trafic provenant d’Istio.
- Génération d’Alertes: Alertmanager analyse les données de Prometheus et déclenche des alertes lorsque le trafic HTTP dépasse un seuil défini.
- Action Automatique: Les alertes d’Alertmanager déclenchent des playbooks Ansible via Event Driven Ansible, qui lancent automatiquement les pods Kubernetes.
- Arrêt Automatique: Lorsqu’il n’y a plus de trafic HTTP pendant une période définie, Alertmanager déclenche un autre playbook Ansible qui arrête les pods.
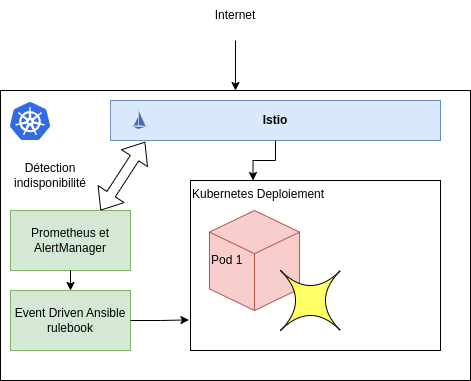
Mise en place de la plateforme¶
Installation de kubernetes+istio¶
Nous utiliserons Google Kubernetes Engine (GKE) avec Node-Autoscaling, qui s’occupe automatiquement de la mise à l’échelle des nœuds. Cela permet d’optimiser les ressources facturables en fonction du nombre de pods en cours d’exécution.
gcloud compute networks create scaleto0-vpc --project $PROJECT_ID
gcloud container clusters create scaleto0-demo \
--enable-autoscaling \
--num-nodes 1 \
--min-nodes 1 \
--max-nodes 3 \
--network scaleto0-vpc \
--project $PROJECT_ID \
--release-channel=regular \
--zone=${REGION}-b
gcloud container clusters get-credentials scaleto0-demo \
--zone=${REGION}-b \
--project=$PROJECT_ID
Ensuite, nous installerons Istio pour la gestion du trafic :
curl -L https://istio.io/downloadIstio | sh -
cd istio-<<VERSION>>
./bin/istioctl install --set profile=demo -y
Vérifiez l’installation d’Istio :
# Vérifier l'état des pods
kubectl get pods -n istio-system
# Vérifier l'état des services et s'assurer qu'un LB externe est créé pour istio-ingressgateway
kubectl get svc -n istio-system
Installation du monitoring : Prometheus / Alertmanager¶
Dans cet article nous réaliserons l’installation d’un système de surveillance minimaliste pour Istio, en se concentrant uniquement sur la surveillance d’Istio lui-même, sans surveiller les serveurs, les CPU ou la RAM. Nous utiliserons un chart Helm pour une installation simplifiée et maintiendrons la cohérence avec le reste de l’article en utilisant l’espace de noms istio-system.
helm upgrade -i -n istio-system prometheus prometheus-community/prometheus -f - << EOF
---
# prometheus_values.yaml
rbac:
create: true
configmapReload:
prometheus:
enabled: false
server:
namespaces:
- istio-system
resources:
limits:
cpu: 100m
memory: 512Mi
requests:
cpu: 100m
memory: 512Mi
global:
scrape_interval: 1s
scrape_timeout: 1s
evaluation_interval: 2s
serverFiles:
prometheus.yml:
rule_files:
- /etc/config/recording_rules.yml
- /etc/config/alerting_rules.yml
scrape_configs:
- job_name: 'istiod'
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scrape]
action: keep
regex: true
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scrape_slow]
action: drop
regex: true
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_scheme]
action: replace
regex: (https?)
target_label: __scheme__
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_path]
action: replace
target_label: __metrics_path__
regex: (.+)
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_port, __meta_kubernetes_pod_ip]
action: replace
regex: (\\d+);(([A-Fa-f0-9]{1,4}::?){1,7}[A-Fa-f0-9]{1,4})
replacement: '[\$2]:\$1'
target_label: __address__
- source_labels: [__meta_kubernetes_pod_annotation_prometheus_io_port, __meta_kubernetes_pod_ip]
action: replace
regex: (\\d+);((([0-9]+?)(\\.|$)){4})
replacement: \$2:\$1
target_label: __address__
- action: labelmap
regex: __meta_kubernetes_pod_annotation_prometheus_io_param_(.+)
replacement: __param_$1
- action: labelmap
regex: __meta_kubernetes_pod_label_(.+)
- source_labels: [__meta_kubernetes_namespace]
action: replace
target_label: namespace
- source_labels: [__meta_kubernetes_pod_name]
action: replace
target_label: pod
- source_labels: [__meta_kubernetes_pod_phase]
regex: Pending|Succeeded|Failed|Completed
action: drop
- source_labels: [__meta_kubernetes_pod_node_name]
action: replace
target_label: node
alertmanager:
enabled: true
kube-state-metrics:
enabled: false
prometheus-node-exporter:
enabled: false
prometheus-pushgateway:
enabled: false
EOF
kubectl create clusterrole prometheus-server --verb=get,list,watch --resource=pods,endpoints,services,nodes,namespaces
kubectl create clusterrolebinding prometheus-server --clusterrole=prometheus-server --serviceaccount=istio-system:prometheus-server
Pour tester le système de monitoring, nous pouvons utiliser la commande suivante afin de rediriger http://localhost:9090 vers le pod Prometheus :
kubectl --namespace istio-system port-forward $(kubectl get pods --namespace istio-system -l "app.kubernetes.io/name=prometheus,app.kubernetes.io/instance=prometheus" -o jsonpath="{.items[0].metadata.name}") 9090
Ouvrez ensuite un navigateur web à l’adresse : http://localhost:9090
Installation d’une application¶
Pour simuler une application dans notre démo, nous allons utiliser “whoami” qui se contente de renvoyer la requête HTTP qu’il reçoit. Si cela fonctionne avec “whoami”, on pourra appliquer le meme principe sur tous les déploiements du cluster Kubernetes.
Créons un fichier YAML pour le déploiement, comme suit :
Ce code YAML décrit la configuration d’un déploiement Kubernetes pour une application nommée “whoami”.
- Déploiement “whoami”: Définit un déploiement avec le nom “whoami” qui utilise l’image Docker “traefik/whoami:latest”. Il indique que le déploiement devrait avoir 1 “replica” (scaling à 1).
- Service “whoami”: Définit un service Kubernetes nommé “whoami” qui se connecte à des pods avec l’étiquette “app: whoami”. Expose le port 80 du service, qui se redirige vers le port 80 du conteneur.
kubectl create ns whoami
kubectl label namespace whoami istio-injection=enabled
kubectl apply -n whoami -f - <<EOF
# whoami_deployment.yaml
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: whoami
annotations:
"sidecar.istio.io/proxyCPU": "500m"
"sidecar.istio.io/proxyMemory": "512Mi"
spec:
selector:
matchLabels:
app: whoami
replicas: 1
template:
metadata:
labels:
app: whoami
spec:
containers:
- name: master
image: traefik/whoami:latest
resources:
requests:
cpu: 500m
memory: 512Mi
limits:
cpu: 500m
memory: 512Mi
ports:
- containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: whoami
labels:
app: whoami
spec:
ports:
- port: 80
targetPort: 80
selector:
app: whoami
EOF
Et exposons ce service via Istio :
kubectl apply -n whoami -f - <<EOF
apiVersion: networking.istio.io/v1alpha3
kind: Gateway
metadata:
name: whoami-gateway
spec:
# The selector matches the ingress gateway pod labels.
# If you installed Istio using Helm following the standard documentation, this would be "istio=ingress"
selector:
istio: ingressgateway
servers:
- port:
number: 80
name: http
protocol: HTTP
hosts:
- "*"
---
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: whoami
spec:
hosts:
- "*"
gateways:
- whoami-gateway
http:
- match:
- uri:
prefix: /
route:
- destination:
port:
number: 80
host: whoami
retries:
attempts: 15
perTryTimeout: 2s
EOF
Test de l’application
INGRESS_HOST=$(kubectl get svc -n istio-system istio-ingressgateway -o jsonpath="{.status.loadBalancer.ingress[0].ip}" )
curl -s -I -HHost:whoami.scaleto0.demo "http://$INGRESS_HOST/"
HTTP/1.1 200 OK
date: Thu, 30 May 2024 20:21:32 GMT
content-length: 570
content-type: text/plain; charset=utf-8
x-envoy-upstream-service-time: 1073
server: istio-envoy
Downscaling de l’application
kubectl -n whoami scale deployment whoami --replicas=0
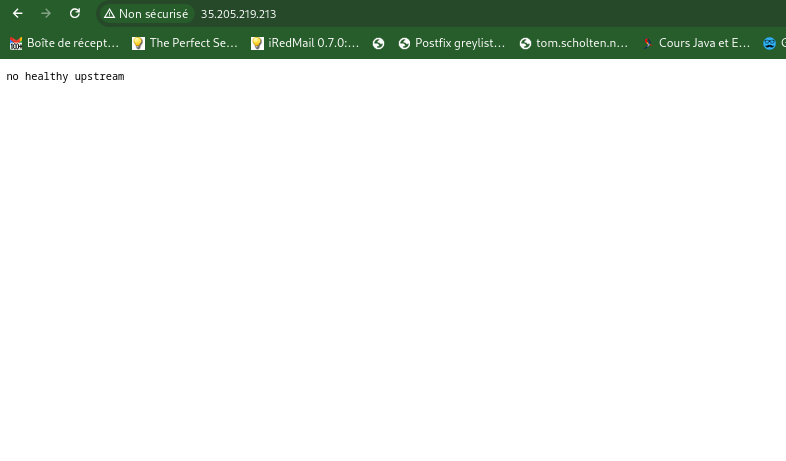
L’appliation une fois coupé (down) ne devrait plus fonctionner : Indisponnibilité de l’application
curl -s -I -HHost:whoami.scaleto0.demo "http://$INGRESS_HOST:$INGRESS_PORT/"
HTTP/1.1 503 Service Unavailable
content-length: 19
content-type: text/plain
date: Thu, 30 May 2024 20:22:56 GMT
server: istio-envoy
Event drivent Ansible¶
En suivant la documentation de Redhat, nous allons construire une image de conteneur pour servir notre rulebook. Voici le fichier Dockerfile qui crée un conteneur pour lancer la commande “ansible-rulebook”.
cat > Dockerfile << EOF
FROM debian:latest
RUN apt-get update && \
apt-get --assume-yes install openjdk-17-jdk python3-pip python3-psycopg && \
pip3 install ansible ansible-rulebook ansible-runner kubernetes --break-system-packages
RUN mkdir /app && \
useradd -u 1001 -ms /bin/bash ansible && \
chown ansible:root /app
WORKDIR /app
USER ansible
RUN ansible-galaxy collection install ansible.eda
ENTRYPOINT ["ansible-rulebook", "-r", "/app/rules.yaml", "-i", "/app/inventory.yml", "-S", "/app"]
EOF
Nous pouvons construire et enregistrer notre image dans artifact-registry de Google :
# Creation du repository
gcloud artifacts repositories create scaleto0-demo-repo --repository-format=docker \
--location=$REGION --description="Docker scaleto0 Demo repository"
# Creation de l'image
gcloud builds submit --region=$REGION --tag $REGION-docker.pkg.dev/$PROJECT_ID/scaleto0-demo-repo/rulebook-scaleto0-demo:v1
Ce conteneur sera déployé dans Kubernetes. Nous allons surcharger le fichier /app/rules.yaml pour y inclure nos règles et playbooks, notamment pour le scaling.
Mise en oeuvre de EDA dans le cluster¶
Construction d’un playbook pour le scaling¶
Ansible, un langage puissant pour la manipulation de composants d’infrastructure, nous permetant de créer un “playbook” qui permettra de scaller le déploiement Kubernetes.
cat > scale-deployment.yaml << EOF
---
- hosts: localhost
connection: local
gather_facts: false
tasks:
- name: Scale deployment up
kubernetes.core.k8s_scale:
api_version: v1
kind: Deployment
name: "{{ deployment_name }}"
namespace: "{{ namespace }}"
replicas: "{{ num_replicas }}"
wait_timeout: 60
EOF
Nous pouvons tester le playbook avec la commande ci-dessous :
ansible-playbook -e '{"deployment_name":"whoami", "namespace":"whoami", "num_replicas": "1"}' scale-deployment.yaml
Ensuite, créons un fichier rules.yaml pour définir l’interface entre le monitoring et le playbook de scaling.
cat > rules.yaml << EOF
- name: Scale deployment up
hosts: localhost
gather_facts: false
sources:
- name: webhook
ansible.eda.webhook:
port: 5000
rules:
- name: whoami
condition: true
actions:
- run_playbook:
name: scale-deployment.yaml
extra_vars:
deployment_name: whoami
namespace: whoami
num_replicas: 1
EOF
cat > inventory.yml << EOF
ungrouped:
hosts:
localhost:
ansible_connection: local
EOF
Injecter le playbook dans Kubernetes :
kubectl create ns ansible-rulebook
kubectl create -n ansible-rulebook configmap ansible-rulebook-config --from-file=.
Démarrer le conteneur:
kubectl -n ansible-rulebook apply -f - << EOF
# ansible-rulebook_deployment.yaml
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: ansible-rulebook
spec:
selector:
matchLabels:
app: ansible-rulebook
replicas: 1
template:
metadata:
labels:
app: ansible-rulebook
spec:
containers:
- name: master
image: $REGION-docker.pkg.dev/$PROJECT_ID/scaleto0-demo-repo/rulebook-scaleto0-demo:v1
resources:
requests:
cpu: 100m
memory: 128Mi
limits:
cpu: 500m
memory: 512Mi
ports:
- containerPort: 5000
volumeMounts:
- name: config
mountPath: /app
volumes:
- name: config
configMap:
name: ansible-rulebook-config
---
apiVersion: v1
kind: Service
metadata:
name: ansible-rulebook
labels:
app: ansible-rulebook
spec:
ports:
- port: 5000
targetPort: 5000
selector:
app: ansible-rulebook
EOF
Accorder des droits à ansible-rulebook pour interagir avec Kubernetes :
kubectl apply -f - << EOF
# ansible-rulebook_clusterrole.yaml
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
creationTimestamp: "2024-05-31T19:01:36Z"
name: deployment-scaler
rules:
- apiGroups:
- apps
resources:
- deployments/scale
- deployments
verbs:
- get
- list
- patch
- update
EOF
Enfin, mapper le rôle ansible-rulebook au déploiement :
kubectl create clusterrolebinding deployment-scaler --clusterrole=deployment-scaler --serviceaccount=ansible-rulebook:default
Intégration avec la supervision¶
Il faut connecter Alertmanager à Ansible rulebook. Pour ce faire, mettons à jour la configuration d’Alertmanager pour qu’elle envoie ses alertes vers le rulebook.
kubectl patch -n istio-system configmap prometheus-alertmanager --type merge -p "
data:
alertmanager.yml: |
global: {}
receivers:
- name: default-receiver
webhook_configs:
- url: http://ansible-rulebook.ansible-rulebook.svc.cluster.local:5000/endpoint
route:
group_interval: 5s
group_wait: 10s
receiver: default-receiver
repeat_interval: 5m
templates:
- /etc/alertmanager/*.tmpl
"
Relancer les pods de monitoring pour prendre en compte le nouveau configmap :
kubectl -n istio-system rollout restart statefulset/prometheus-alertmanager
Création de l’alerte de supervision¶
Créons une alerte de supervision qui détectera les erreurs 503 dans Prometheus et déclenchera le “rulebook” Ansible.
Étant donné que Prometheus est installé avec Helm, nous mettrons à jour la configuration statique pour injecter l’alerte. Dans un environnement de production, les alertes seraient injectées via l’opérateur et les CRD “PrometheusRules”.
kubectl patch -n istio-system configmap prometheus-server --type merge -p "
data:
alerting_rules.yml: |
groups:
- name: DeploymentDown
rules:
- alert: DeploymentDown
expr: sum by (destination_service_name) (rate(istio_requests_total{response_code=\"503\"}[3s])) > 0
for: 2s
labels:
severity: page
annotations:
description: 'No upstream on {{ \$labels.destination_service_name }}'
summary: '{{ \$labels.destination_service_name }} down'
"
Relancer les pods de monitoring pour prendre en compte le nouveau configmap :
kubectl -n istio-system rollout restart deployment/prometheus-server
Après avoir généré quelques appels vers l’application sans pods, nous devrions retrouver l’alerte dans Prometheus :
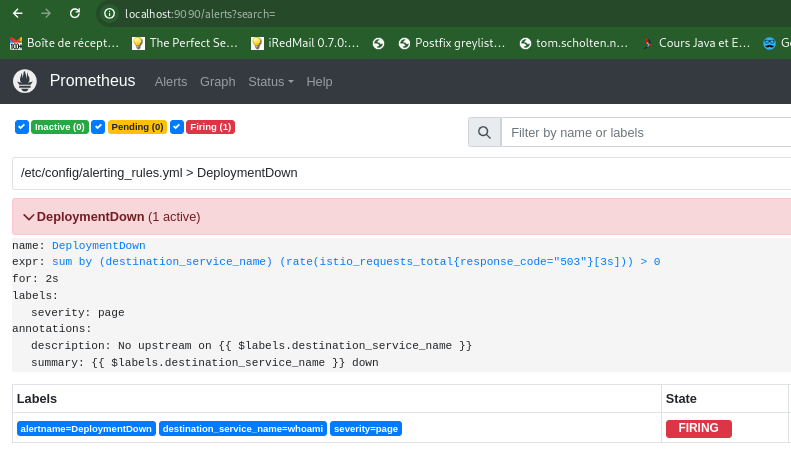
Test du scaling à zéro¶
1. Test de base:
-
Scénario: Démarrez l’application “whoami” avec un seul pod et observez que l’application est accessible.
-
Accédez au service “whoami” via un navigateur ou curl : Verifier que le résultat est correct et garder la fenetre ouverte pour visualiser le status de l’application.
INGRESS_HOST=$(kubectl get svc -n istio-system istio-ingressgateway -o jsonpath="{.status.loadBalancer.ingress[0].ip}" )
watch curl -s -I -HHost:whoami.scaleto0.demo "http://$INGRESS_HOST/"
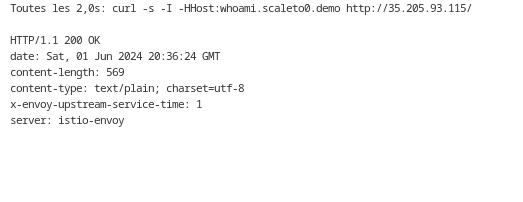 * Assurez-vous que vous obtenez une réponse HTTP 200 et que le contenu renvoyé correspond à l’application “whoami”.
* Vérifiez que le pod “whoami” est en cours d’exécution dans le cluster Kubernetes.
* Assurez-vous que vous obtenez une réponse HTTP 200 et que le contenu renvoyé correspond à l’application “whoami”.
* Vérifiez que le pod “whoami” est en cours d’exécution dans le cluster Kubernetes.
$ kubectl -n whoami get pod
NAME READY STATUS RESTARTS AGE
whoami-5d696b585d-twv98 2/2 Running 0 4m58s
2. Test du scaling à zéro:
- Scénario: Mettez l’application “whoami” à zéro pods et déclenchez des requêtes HTTP vers l’application.
- Validation:
- Utilisez la commande
kubectl -n whoami scale deployment whoami --replicas=0pour réduire le nombre de pods à zéro. - Effectuez plusieurs requêtes HTTP vers l’application “whoami” (via un navigateur ou curl).
- Assurez-vous que les requêtes retournent une réponse HTTP 503 (service indisponible).
- Vérifiez que le monitoring Prometheus détecte l’absence de pod et génère une alerte.
- Vérifiez que l’alerte “DeploymentDown” est générée par Alertmanager et envoyée au webhook d’Ansible.
- Vérifiez que le playbook Ansible “scale-deployment.yaml” est exécuté et qu’un nouveau pod “whoami” est crée
kubectl -n ansible-rulebook logs deployment/ansible-rulebook
De mon côté j’ai observé que le service répond en 25seconde après une coupure.
Conclusion¶
L’autoscaling basé sur les événements offre un équilibre parfait entre l’optimisation des ressources et la disponibilité immédiate des applications. En combinant Event Driven Ansible et des outils tels qu’Istio, Prometheus et Alertmanager, vous pouvez mettre en place un système robuste et efficace pour garantir une performance optimale et des coûts réduits.
Principaux avantages de cette approche¶
- Disponibilité immédiate : Les pods sont lancés automatiquement lors des premiers appels HTTP, garantissant une réponse rapide aux demandes.
- Optimisation des ressources : Les pods sont arrêtés automatiquement lorsqu’ils ne sont plus utilisés, ce qui réduit les coûts de ressources.
- Efficacité et fiabilité : Le système fonctionne de manière automatique et fiable, sans intervention humaine.
- Évolutivité : La solution peut être facilement adaptée aux besoins évolutifs des applications.
Questions pour réflexion¶
- Avez-vous déjà mis en place des solutions similaires pour le scaling à zéro dans vos environnements Kubernetes ?
- Comment pouvez-vous adapter cette solution à vos besoins spécifiques et l’intégrer dans votre pipeline DevOps ?
Ressources supplémentaires¶
- https://chimbu.medium.com/installing-istio-not-anthos-service-mesh-on-gke-autopilot-2b78f1bbe90a
- https://developers.redhat.com/articles/2024/04/12/event-driven-ansible-rulebook-automation#ansible_rulebook_cli_setup
- https://github.com/istio/istio/issues/10543#issuecomment-921179277
- https://medium.com/@letsretry/retry-between-region-using-ingress-controller-ingress-level-retry-e8c000580bfe