 Cloud Ops Chronicles
Cloud Ops Chronicles
J'ai automatisé ma veille technologique avec un Podcast généré par IA (Gemini & Cloud Run)
- L’Architecture “Serverless”
- Étape 1 : La Source de Données (BigQuery)
- Étape 2 : Le Scénariste (Gemini 3 Pro)
- Étape 3 : Le Studio Audio (Gemini 2.5 Flash TTS)
- Étape 4 : Le Graphiste (Imagen 3)
- Étape 5 : La Diffusion (FastAPI & RSS)
- Étape 6 : L’Infrastructure as Code (Terraform)
- Étape 7 : Le Pipeline CI/CD (GitLab CI & Cloud Deploy)
- Le Coût (FinOps)
Vous n’avez pas le temps de lire les centaines de release notes publiées par Google Cloud chaque semaine ? Moi non plus. C’est pour cela que j’ai créé le GCP News Podcast.
🎙️ Écoutez le résultat final ici : podcast.kapable.info
Ce projet n’est pas juste une démo, c’est un pipeline de production entièrement automatisé “Serverless” qui :
- Récupère l’actualité technique brute.
- Scénarise un dialogue entre deux experts virtuels (Marc et Sophie).
- Génère l’audio avec un réalisme bluffant (intonations, rires, pauses).
- Crée une couverture d’album unique pour chaque épisode.
- Publie le tout sur le web et les plateformes de podcast (Spotify, etc.).
Voici comment j’ai construit ce système.
L’Architecture “Serverless”¶
Le système est conçu pour coûter près de zéro lorsqu’il ne tourne pas. Il s’appuie sur une architecture événementielle et des services managés.
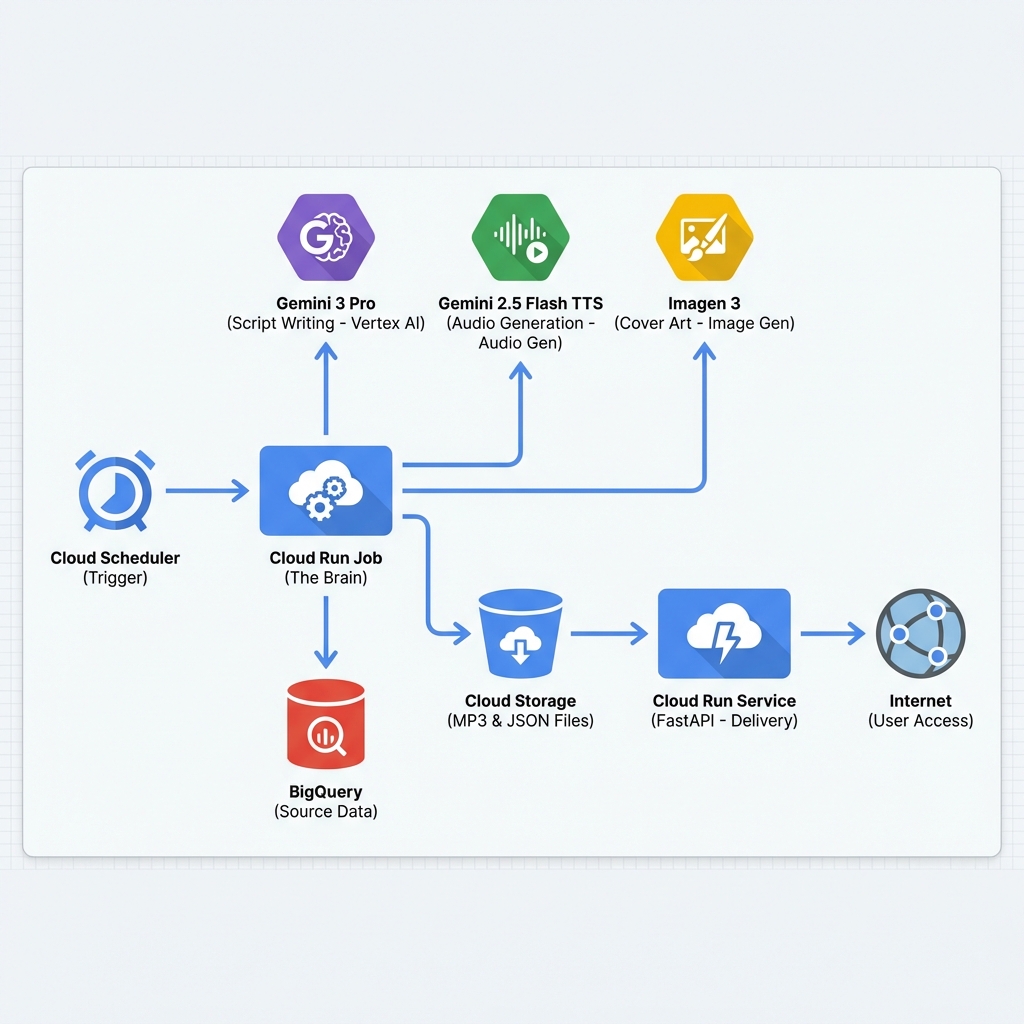
Le Code (Open Source)¶
Tout le code est disponible sur GitLab : matgou/podcast-generator.
Il est divisé en deux parties :
* generator/ : Le script Python batch qui crée l’épisode.
* frontend/ : L’interface web FastAPI pour écouter les épisodes.
Étape 1 : La Source de Données (BigQuery)¶
Contrairement à beaucoup de projets qui font du “scraping”, ici nous utilisons une source de vérité propre : le dataset public BigQuery de Google.
Le script exécute une simple requête SQL pour récupérer tout ce qui a changé depuis 7 jours.
QUERY = """
SELECT description, published_at, product_name
FROM `bigquery-public-data.google_cloud_release_notes.release_notes`
WHERE published_at > DATE_SUB(CURRENT_DATE(), INTERVAL 7 DAY)
ORDER BY published_at DESC
"""
Cela nous donne une liste brute de texte, souvent très aride et technique. C’est là que l’IA entre en jeu.
Étape 2 : Le Scénariste (Gemini 3 Pro)¶
Nous injectons ces notes brutes dans Gemini 3 Pro avec un prompt système très spécifique (le prompt_template.txt).
Le but n’est pas de résumer, mais de scénariser. * Marc est l’expert technique, précis et factuel. * Sophie est l’animatrice curieuse, qui pose les questions que l’auditeur se poserait.
L’une des fonctionnalités clés utilisées ici est le Grounding avec Google Search. Cela permet à Gemini de vérifier les faits et d’ajouter des liens vers la documentation officielle dans les métadonnées de l’épisode.
// Exemple de sortie structurée JSON attendue de Gemini
{
"title": "Cloud Run s'accélère et BigQuery se sécurise",
"summary": "Cette semaine, Marc et Sophie discutent des nouvelles instances...",
"script": "Sophie: Bonjour à tous ! ... Marc: Exactement, et c'est majeur...",
"image_prompt": "An abstract representation of a fast server race in a neon city..."
}
Étape 3 : Le Studio Audio (Gemini 2.5 Flash TTS)¶
C’est la partie la plus impressionnante. Nous n’utilisons pas l’ancien “Text-to-Speech” robotique. Nous utilisons le modèle Gemini 2.5 Flash TTS (encore en preview), capable de générer plusieurs locuteurs dans le même flux audio.
Le prompt définit les personnalités vocales :
* Marc utilise la voix Fenrir.
* Sophie utilise la voix Laomedeia.
Le script Python appelle directement l’API REST de Vertex AI pour générer l’audio.
# Extrait simplifié de l'appel API
payload = {
"contents": [{"parts": [{"text": script_text}]}],
"generationConfig": {
"speechConfig": {
"multiSpeakerVoiceConfig": {
"speakerVoiceConfigs": [
{"speaker": "Marc", "voiceConfig": {"prebuiltVoiceConfig": { "voiceName": "Fenrir" }}},
{"speaker": "Sophie", "voiceConfig": {"prebuiltVoiceConfig": { "voiceName": "Laomedeia" }}}
]
}
}
}
}
Étape 4 : Le Graphiste (Imagen 3)¶
Pour rendre le podcast visuel sur les plateformes, il nous faut une couverture. Gemini (le scénariste) a déjà généré un image_prompt basé sur le contenu de l’épisode.
Nous passons ce prompt à Imagen 3 via Vertex AI pour générer une image carrée (1:1), que nous redimensionnons et compressons pour respecter les standards d’Apple Podcasts (1400x1400, <512KB).
Étape 5 : La Diffusion (FastAPI & RSS)¶
Une fois tous les fichiers générés (MP3, JSON, JPG, YAML), ils sont stockés sur Google Cloud Storage.
Le Frontend (une app FastAPI sur Cloud Run) ne stocke rien. Il agit comme une interface de lecture sur le Bucket GCS.
Le Flux RSS Dynamique¶
Pour s’abonner sur Apple Podcast ou Spotify, il faut un flux RSS XML conforme. L’application génère ce flux à la volée (/feed.xml) en lisant les manifestes des épisodes présents dans le bucket.
Elle gère aussi :
* La signature d’URL (Signed URLs) pour sécuriser l’accès aux fichiers audio.
* Les headers HTTP HEAD nécessaires pour la validation par les agrégateurs de podcasts.
Étape 6 : L’Infrastructure as Code (Terraform)¶
Pour éviter de cliquer partout dans la console Google Cloud, toute l’infrastructure est définie en Terraform.
Cela permet de créer des environnements reproductibles (Preprod, Prod) et de gérer les permissions finement.
# Extrait de infra/production/main.tf
module "podcast_generator" {
source = "../modules/podcast-generator"
project_id = var.project_id
region = var.region
bucket_name = "${var.project_id}-podcast-output"
# Configuration du Job et du Service
podcast_model = "gemini-3.0-pro-preview"
schedule_cron = "0 9 * * 1" # Tous les lundis à 9h
}
Étape 7 : Le Pipeline CI/CD (GitLab CI & Cloud Deploy)¶
Le déploiement est entièrement automatisé via GitLab CI et Google Cloud Deploy.
- GitLab CI : Construit les images Docker (Generator & Frontend) et les pousse sur Artifact Registry.
- Cloud Deploy : Récupère ces images, génère les manifestes Kubernetes (YAML) via un script et déploie le tout sur Cloud Run.
Le pipeline gère la promotion du code de la pré-production vers la production sans intervention manuelle risquée.
Le Coût (FinOps)¶
C’est la meilleure partie. Comme l’architecture est “Scale to Zero”, je ne paie que lorsque le podcast est généré ou écouté.
Coût mensuel réel : ~0,20 €
- Cloud Run (Job) : Quelques centimes pour les 2-3 minutes de génération par semaine.
- Cloud Run (Service) : Gratuit (dans le Free Tier) car peu de trafic.
- Vertex AI : Le plus gros poste, mais reste très faible pour une utilisation hebdomadaire.
- Cloud Storage : Négligeable pour quelques fichiers MP3.
C’est une solution extrêmement économique pour un média entièrement automatisé.
Ce projet démontre la puissance de la GenAI Multimodale. En moins de 500 lignes de code Python, nous avons remplacé toute une chaîne de production médiatique (recherche, écriture, enregistrement, graphisme).
Le résultat est une veille technologique agréable à écouter, toujours à jour, et qui tourne toute seule chaque lundi matin pendant que je prends mon café. ☕
Liens utiles : * 🎧 Le Podcast * 🛠️ Code Source (GitLab)