 Cloud Ops Chronicles
Cloud Ops Chronicles
Le Workflow "AI-First" : Quand votre IDE ne démarre que pour valider l'IA
- L’ère du développeur-validateur
- Le nouveau cycle de vie : de la Feature à la Release
- Pourquoi Nix ? L’arme secrète du déterminisme
- Les dessous de l’architecture : abattre les murs pour les workstations Serverless
- Le nerf de la guerre : Pourquoi le Scale-to-Zero change tout pour le budget
- Architecture du projet et pipeline de build
- Pour démarrer
Une Workstation VS Code reproductible sur Cloud Run, propulsée par Nix, conçue pour les boucles de collaboration Humain-IA — avec un coût de 0,00 $ au repos.
🔗 Source du projet : gitlab.com/matgou/workstation-nix
L’ère du développeur-validateur¶
Il y a encore peu de temps, nos environnements de développement vivaient sur nos machines, lourds et personnalisés à l’excès. Puis sont arrivés les IDE Cloud (GitHub Codespaces, Google Cloud Workstations), pensés pour une ère bien précise : celle de développeurs humains codant activement 8 heures par jour en utilisant la puissance de serveurs déportés.
Mais l’émergence de l’IA générative bouleverse aussi cette donne. Aujourd’hui, face à la génération de code, on a besoin de GPU : locaux (pas chers), distants (chers) et, en plus, deux visions s’affrontent et on verra bien laquelle perdurera :
- L’école du “les IA seront bientôt 100% autonomes” : Le développeur ne maintient plus que des spécifications en Markdown, l’IA fait tout le reste, de bout en bout.
- L’école du “L’IA prépare, l’humain valide” : L’IA abat le gros du travail, mais le développeur aura toujours un rôle de garant du code produit. Il sera amené à “mettre les mains dedans” pour tester, valider et ajuster.
Soyons pragmatiques : la première école relève encore (pour l’instant) de la science-fiction pour la majorité des projets complexes ou critiques en entreprise. Et je suis d’avis que nous avons pour l’instant toujours besoin de mettre les mains dans le cambouis pour auditer et valider le code généré. Cependant, je constate que nos outils n’ont pas suivi, l’adoption des EDI déportés est encore trop anecdotique. Et payer un environnement permanent alors que l’humain n’intervient plus qu’en pointillé n’a aucun sens économique — et même écologique.
Je vous propose ici une réflexion autour des nouveaux EDI déportés et souhaite montrer qu’ils sont accessibles à tous avec, comme exemple, la mise en place d’une Workstation-CloudRun. Ces derniers, bien que n’ayant pas été construits précisément pour ce monde de symbiose entre le développeur et l’agent IA, s’y adaptent pourtant parfaitement. Aujourd’hui chacun peut disposer d’un EDI surpuissant, avec des GPUs, sur mesure, disponible instantanément, qui ne vit que le temps exact où nous avons besoin de réviser le code (et pas pendant que l’IA travaille).
Le nouveau cycle de vie : de la Feature à la Release¶
Pour bien comprendre la nouvelle dynamique du développement piloté par les agents IA, il faut repenser notre pipeline de livraison. L’humain n’est plus à l’origine du code, il en devient le validateur final.
Voici une vision d’un workflow moderne :
- Les spécifications d’un ticket ou d’une modification sont communiquées. (Je ne vais pas détailler ici comment écrire et faire valider de bonnes spécifications pour que l’IA puisse les traiter.)
- L’IA travaille dans l’ombre : Un agent IA (Gemini, Claude, ou un pipeline CI autonome) échafaude un projet, écrit une feature ou résout un bug.
- Le point de convergence : L’agent dépose tout ce code directement dans un grove — un bucket Google Cloud Storage (GCS) servant d’espace de travail partagé. J’ai emprunté le terme “grove” au framework Google Scion. (Coût : 0 $, le stockage objet étant quasi gratuit).
- Le passage de relais (Hand-off) : L’IA vous notifie que le code est prêt à être validé ou complété par l’humain.
- L’Humain prend la main : Vous cliquez sur une URL Cloud Run. En quelques secondes, une instance VS Code démarre dans la Workstation Nix. Le code généré par l’IA est déjà là, monté instantanément. Dans cette workstation, vous pouvez modifier, lancer, déboguer le code, ou même le vibecoder.
- Scale to Zero : Une fois la PR validée, vous fermez l’onglet. L’instance Cloud Run s’éteint. Vous ne payez plus.
Voici comment se matérialise ce cycle, de la requête initiale jusqu’à la release :
flowchart LR
A["🎯 Feature Request"] --> B{"🤖 Agent IA"}
B ==>|"git clone + code"| C[("☁️ Grove (GCS)")]
D["💻 Workstation Nix"] -->|"GCS FUSE mount"| C
B --> |"spawn"| D
E{"👨💻 Humain"} --> |"review, test, fix"| D
E -->|"git merge"| F[("🚀 Git Release")]
style A fill:#4285f4,color:#fff,stroke:none
style B fill:#ea4335,color:#fff,stroke:none
style C fill:#fbbc04,color:#333,stroke:none
style D fill:#34a853,color:#fff,stroke:none
style E fill:#ea4335,color:#fff,stroke:none
style F fill:#4285f4,color:#fff,stroke:none
Le gros avantage d’un workflow comme celui-ci est entre autres le principe du Scale to Zero : c’est-à-dire que le coût total au repos : 0,00 $ — En effet, le grove (GCS) ne coûte que quelques centimes de stockage. La Workstation ne consomme des ressources que pendant la validation humaine.
Des IA qui manipulent du code, ça semble maintenant classique, mais VS Code dans Cloud Run, c’est un concept. Pour le rendre fonctionnel et reproductible, il faut parfois contourner certaines limites. Ce projet est un bon exemple de comment repousser les limites de cette technologie.
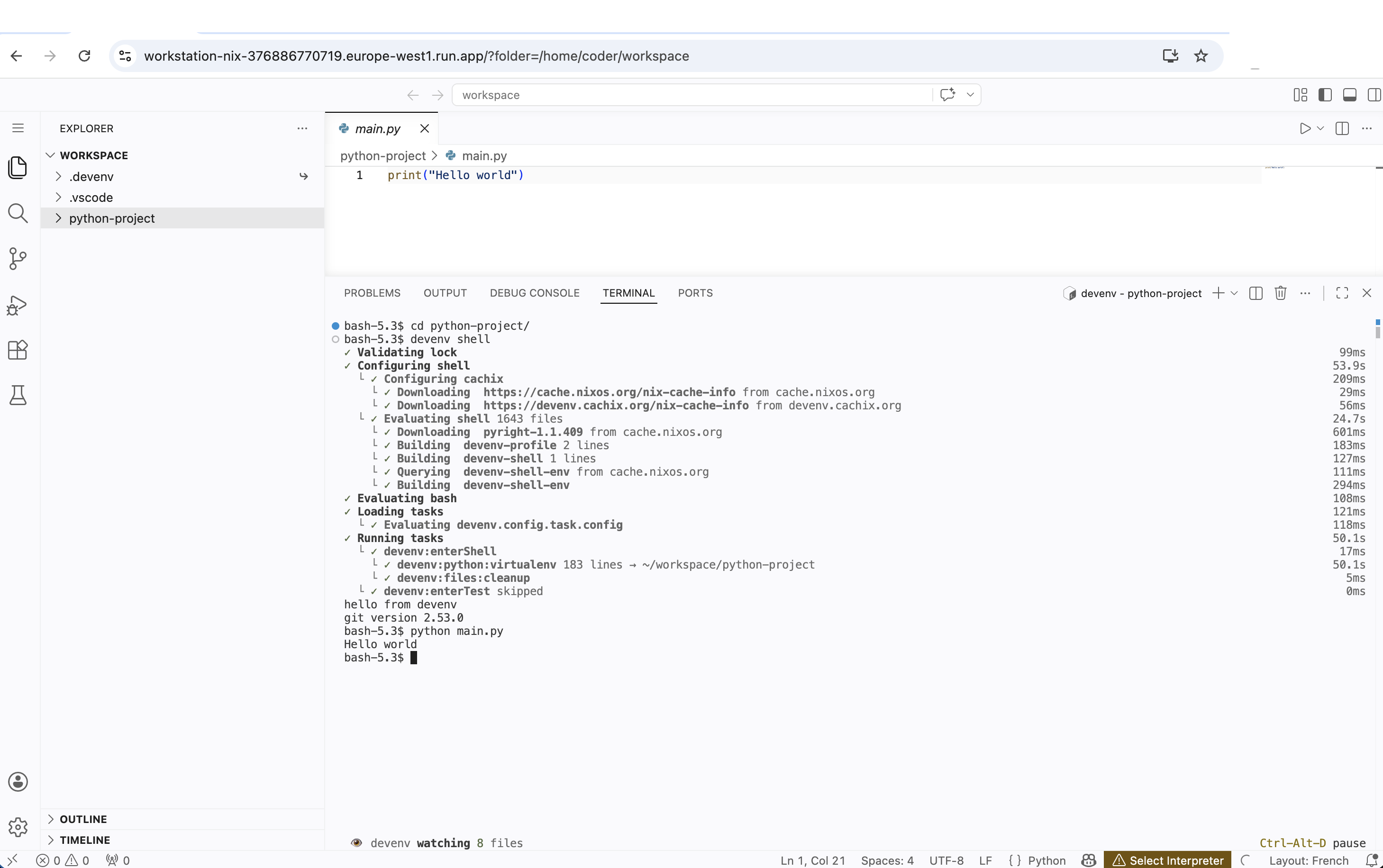
Pourquoi Nix ? L’arme secrète du déterminisme¶
Dans ce projet, il faut garantir que l’environnement dans lequel s’exécute le code est reproductible et qu’il disposera de tous les outils nécessaires aux suites de tests et au développement.
Un des défis est donc que l’environnement soit reproductible mais non figé (par exemple, si on compile un conteneur Docker, on embarque toutes les dépendances de manière statique mais aussi les failles de sécurité).
C’est ici que Nix entre en jeu en remplaçant l’approche impérative par une approche purement fonctionnelle. Chaque dépendance est managée as code et embarque son arbre de dépendances complet. “Le package.json/package-lock de la workstation” en quelque sorte.
Voici pourquoi Nix est devenu indispensable pour cette architecture :
- Reproductibilité bit-à-bit : Le même fichier flake.lock (généré par l’IA ou le template) produit toujours exactement la même image.
- Composition atomique : Ajouter un outil se résume à une ligne.
coreTools = with pkgs; [
bashInteractive coreutils curl git jq neovim nix ripgrep
];
Chaque binaire — de bash à code-server — est tiré du Nix Store avec sa version exacte. Nix génère ensuite l’image Docker finale pour nous via pkgs.dockerTools.buildLayeredImage, sans même avoir besoin d’un daemon Docker complexe.
- Pas d’artefacts à stocker : Seul le fichier de code flake.nix est à stocker. La beauté de la chose, c’est que si l’on change de machine, on repart avec la même configuration.
C’est exactement le choix qui a été fait par devenv.sh, un projet open source de Cachix qui standardise la définition d’environnements de développement au-dessus de Nix. Son principe : décrire son environnement dans un simple fichier devenv.nix avec une syntaxe déclarative — langages, paquets, services, scripts — et laisser Nix matérialiser le tout de façon reproductible. Activating Python, Rust ou PostgreSQL se résume à une ligne (languages.python.enable = true;), l’activation d’un environnement se fait en moins de 100 ms grâce au cache, et le tout reste décorable via des profils et des imports.
Notre Workstation-CloudRun s’intègre naturellement avec le standard devenv. Une fois connecté à l’IDE, le développeur peut simplement lancer devenv shell dans le terminal VS Code pour activer l’environnement déclaré dans le dépôt du projet hébergé sur le grove. Les outils, les versions, les services — tout est déjà défini as code par l’équipe ou par l’IA. Le développeur n’a rien à installer manuellement : l’environnement de développement est aussi éphémère et reproductible que la workstation elle-même.
Les dessous de l’architecture : abattre les murs pour les workstations Serverless¶
Sur le papier, faire tourner un IDE web comme VS Code sur Cloud Run semble facile. Nix propose un système de build permettant de créer des conteneurs. Mais dans la pratique (et particulièrement d’un point de vue DevSecOps), les plateformes Serverless ne sont pas du tout conçues pour héberger des environnements stateful avec des accès terminaux complexes.
Pour transformer cette vision en réalité, j’ai dû affronter et contourner quelques limites techniques majeures de l’écosystème cloud actuel. Je vous propose un petit retour d’expérience sur les problèmes rencontrés :
Mur n°1 — Le terminal qui refuse de s’ouvrir¶
Nous allons utiliser le terminal de VS Code pour interagir avec l’environnement. Mais manipuler un terminal oblige à interagir avec le noyau du système.
Le noyau gVisor par défaut (Gen1) de Cloud Run ne supporte pas les pseudo-terminaux (/dev/ptmx).
La solution : Passer au moteur d’exécution Cloud Run de seconde génération (--execution-environment gen2). Cela exécute le conteneur dans une véritable micro-VM Linux. Nous montons ensuite devpts manuellement au démarrage pour débloquer les terminaux VS Code.
Mur n°2 — Les WebSockets vs. la couche proxy¶
La commande gcloud run services proxy, qui permet d’accéder à un service Cloud Run via un tunnel local, ne supporte pas les connexions WebSocket. Or, VS Code (code-server) repose massivement sur les WebSockets pour le terminal et l’édition en temps réel. Résultat : des freezes aléatoires du terminal et des déconnexions en pleine session. Ce problème bloque de facto l’utilisation d’IAP (Identity-Aware Proxy) comme couche d’authentification, puisque le proxy en est le point d’entrée.
Une alternative aurait été de placer un Load Balancer avec IAP devant Cloud Run — solution propre mais qui introduit un coût fixe permanent (~18 $/mois pour la règle de forwarding), ce qui va à l’encontre de notre philosophie Scale-to-Zero à coût nul au repos.
La solution pragmatique : Exposer Cloud Run directement (avec son URL HTTPS native) et déléguer la sécurité au mécanisme natif --auth password de code-server, qui est pleinement compatible WebSocket. Le timeout de l’instance Cloud Run est également poussé à son maximum légal (3600 secondes) pour garantir une session ininterrompue, et le nombre maximum d’instances est verrouillé à 1 (--max-instances 1) pour garantir une session unique et maîtriser les coûts.
Mur n°3 — Le stockage partagé Humain / IA¶
À chaque scale-to-zero, le conteneur disparaît. Il nous fallait un espace persistant où l’IA peut déposer le code et où la workstation peut modifier et le récupérer. Puis le reprendre en cas de stop/start du conteneur. Le but étant de pouvoir travailler sur un projet, de l’abandonner et de le reprendre plus tard sans perdre son travail. Idéal pour les périodes d’essai.
La solution : GCS FUSE et le mirage des permissions POSIX :
Un bucket Cloud Storage monté via GCS FUSE semblait la solution évidente. Cependant, un nouveau mur est apparu : GCS n’est pas un système de fichiers POSIX et ne gère pas nativement les changements de permissions (les fameux chmod et chown).
Conséquence ? Des outils modernes comme devenv, npm ou git, qui tentent de sécuriser leurs fichiers temporaires ou environnements virtuels, plantaient lamentablement avec une erreur fatale : Operation not permitted.
Pour contourner cette limitation stricte sans sacrifier la persistance temps réel, nous avons “trompé” l’outil de montage FUSE en forçant une simulation totale des permissions pour notre utilisateur exclusif. Voici la configuration de montage Cloud Run optimisée pour l’IDE (quelques options de performances ont aussi été ajoutées) :
implicit-dirs
stat-cache-max-size-mb=32 # Alloue 32 Mo en RAM pour le cache des métadonnées
metadata-cache-ttl-secs=300 # Garde les métadonnées en cache pendant 5 minutes
enable-streaming-writes=true # Écritures en streaming direct
client-protocol=http1 # (Performance) Forcer HTTP/1.1 pour éviter le Head-of-Line blocking HTTP/2
max-conns-per-host=100 # (Performance) Massifier les I/O parallèles
cache-dir=cr-volume:cache # Indique à Cloud Run d'utiliser notre volume in-memory nommé "cache"
file-cache-max-size-mb=2048 # Alloue 2Go de RAM pour ce cache
uid=1000 # Force l'appartenance à l'utilisateur VS Code
gid=1000
file-mode=0777 # Simule une permissivité totale
dir-mode=0777
L’Asynchronisme et la gestion des petits fichiers :
Créer un environnement virtuel (ex: python -m venv) implique la création de milliers de petits fichiers. Avec un montage réseau classique et le protocole HTTP/2 par défaut de GCS FUSE, toutes ces requêtes s’empilent de manière synchrone sur une seule connexion TCP.
Nous forçons donc le protocole HTTP/1.1 (client-protocol=http1), ouvrons un pool de 100 connexions simultanées pour paralléliser massivement les écritures. De plus, nous conservons un cache local en RAM (cache-dir=cr-volume:cache) de 2 Go pour accélérer considérablement la lecture du code source existant.
Cependant, il faut être conscient des limites du Serverless : même avec cette parallélisation et ces caches agressifs, la latence réseau synchrone incompressible de Google Cloud Storage reste un goulot d’étranglement pour la création pure d’arborescences massives. Voici l’évolution des performances mesurées pour la création d’un environnement Python (devenv shell) sur notre architecture Cloud Run :
| Configuration GCS FUSE | Temps de création du venv |
Bilan |
|---|---|---|
| Standard (HTTP/2 par défaut) | ~ 9 min 42 s | Inutilisable au quotidien |
| Optimisé (HTTP/1.1 + max-conns=100 + Caches RAM) | ~ 8 min 44 s | Mieux, mais la latence synchrone bride le réseau |
Optimisé + Déport .devenv en RAM (Symlink) |
~ 45 secondes | Performances quasi locales ! |
L’ultime parade (implémentée via un wrapper transparent au sein même de l’image Nix) consiste à déporter le dossier d’état local .devenv dans la RAM (tmpfs) à l’aide d’un lien symbolique dynamique. Puisque le /nix/store est recréé à chaque démarrage de l’instance, le dossier d’état de l’environnement est par essence éphémère. En le générant en RAM, la création de milliers de fichiers devient atomique et immédiate.
Le développeur conserve ainsi un environnement persistant pour son code via GCS FUSE (bénéficiant des options de cache pour la réactivité de lecture), tout en esquivant totalement la latence GCS pour la création de l’outillage lourd.
Grâce aux drapeaux uid, gid et mode, GCS FUSE considère de plus que l’utilisateur possède déjà tous les droits. Lorsqu’un outil demande un chmod, GCS FUSE renvoie un code de succès factice au lieu de crasher. Le développeur obtient ainsi un environnement de développement persistant, tout en évitant les crashs liés aux exigences POSIX.
Mur n°4 — Tourner en non-root avec Nix (Sécurité)¶
Faire tourner un IDE en root complet est une hérésie de sécurité. Mais Nix a besoin d’écrire dans /nix/store pour installer des paquets. La solution naïve — donner l’ownership du store entier à l’utilisateur coder (mode single-user) — est un anti-pattern de sécurité : l’utilisateur pourrait alors modifier n’importe quel binaire du système.
La solution : Utiliser le mode multi-user de Nix avec nix-daemon. Le conteneur démarre en root, lance le daemon Nix en arrière-plan (qui reste root et gère exclusivement le store), puis abandonne irrévocablement ses privilèges via gosu avant de lancer l’IDE sous l’UID 1000. Ainsi, le /nix/store reste en lecture seule pour l’utilisateur coder — il peut installer de nouveaux paquets via le daemon (qui vérifie et écrit pour lui), mais ne peut jamais altérer les binaires existants. C’est la même architecture que celle utilisée sur les machines NixOS de production.
Quelques petites optimisations supplémentaires qui concernent Nix :
- Bypass du disque réseau : Nous forçons export TMPDIR=/tmp/cache pour orienter les builds vers notre volume in-memory ultra-rapide (RAM-disk de 4 Go monté spécialement pour l’occasion).
- Mise au pas de Nix : Nous bloquons la parallélisation sauvage en forçant max-jobs = 4 et cores = 2 dans la configuration de Nix pour respecter les vCPU réellement alloués au conteneur.
Le nerf de la guerre : Pourquoi le Scale-to-Zero change tout pour le budget¶
Maintenant que nous avons réussi à packager Nix et VS Code dans un conteneur, nous pouvons l’utiliser avec une approche Cloud Run. Voici ce que ça change en termes de coûts.
L’approche Serverless brille particulièrement dans ce workflow hybride, car il permet de ne payer que ce qu’on consomme. Pour illustrer cela, prenons un scénario réaliste d’entreprise : un mois de travail standard (environ 160 heures) pour un développeur alternant entre validation IA et code manuel.
Dans un modèle cloud classique, votre environnement tourne (et vous facture) pendant ces 160 heures, que vous soyez en train de taper du code, en réunion, ou d’attendre qu’une IA finisse son travail. Regardons l’impact financier de notre approche face aux ténors du marché :
| Google Cloud Workstations | GitHub Codespaces (4-core) | Notre Cloud Run Workstation | |
|---|---|---|---|
| Coût mensuel (160h) | ~192 $ | ~61 $ | ~28 $ |
| Coût d’attente (idle) | ~171 $ (Control plane 24/7) | ~3,50 $ (Stockage persistant) | 0 $ |
| Pénalité Asynchrone | L’instance tourne à vide | Le stockage est facturé | Seul le bucket GCS est facturé (< 1$) |
Comment lire ce tableau ? La différence radicale (28$ contre 192$) s’explique par la suppression pure et simple du coût d’attente. Si l’IA prépare une grosse feature le lundi, mais que vous ne trouvez le temps de la réviser que le jeudi pendant 2 heures, Cloud Run ne vous aura coûté que 0,40 $ sur toute la semaine. Les autres solutions vous facturent des frais fixes en continu.
Architecture du projet et pipeline de build¶
Une des étapes du projet est la création d’un conteneur de base qui sera utilisé par Cloud Run et l’autre partie du projet consiste en la création d’un catalogue GitLab permettant de préparer le code pour la reprise par la workstation.
Le conteneur de base¶
Le projet est volontairement minimaliste — trois dossiers, zéro framework superflu :
workstation-nix/
├── base-oss/ # 🏗️ Golden Image Nix
│ ├── flake.nix # Définition déclarative de l'image Docker
│ ├── flake.lock # Verrouillage des dépendances (reproductibilité)
│ └── .trivyignore # CVE acceptées (revue mensuelle)
├── terraform/ # ☁️ Infrastructure as Code
│ ├── main.tf # APIs GCP, Artifact Registry, Secret Manager
│ ├── iam.tf # Service Account & rôles (moindre privilège)
│ ├── variables.tf # Variables du projet
│ └── provider.tf # Configuration du provider GCP
├── cloudbuild.yaml # 🔄 Pipeline CI/CD (Cloud Build)
└── Makefile # 🎯 Point d'entrée développeur (init/build/deploy)
base-oss/flake.nix est le cœur du projet : il définit de manière purement déclarative tous les outils embarqués dans la Golden Image (bash, git, code-server, nix…) et génère l’image Docker via pkgs.dockerTools.buildLayeredImage — sans Dockerfile, sans daemon Docker.
terraform/ provisionne l’infrastructure GCP nécessaire : activation des APIs, création de l’Artifact Registry pour stocker les images, du Secret Manager pour le mot de passe IDE, et du Service Account avec le principe du moindre privilège.
cloudbuild.yaml orchestre le pipeline CI/CD complet. Voici le flux de bout en bout, du git push à l’image déployable :
flowchart LR
A["📦 git push"] --> B["🔨 Nix Build\n(nixos/nix)"]
B -->|"image.tar.gz"| C["🐳 Docker Load\n& Tag"]
C --> D["🔍 Trivy Scan\n(CRITICAL/HIGH)"]
D -->|"✅ Pass"| E["📤 Push\nArtifact Registry"]
D -->|"❌ Fail"| F["🚫 Build\nBloqué"]
style A fill:#4285f4,color:#fff,stroke:none
style B fill:#34a853,color:#fff,stroke:none
style C fill:#4285f4,color:#fff,stroke:none
style D fill:#fbbc04,color:#333,stroke:none
style E fill:#34a853,color:#fff,stroke:none
style F fill:#ea4335,color:#fff,stroke:none
Le pipeline se décompose en 4 étapes :
1. Nix Build — Le conteneur nixos/nix évalue flake.nix et produit une archive Docker layered (image.tar.gz). Aucune dépendance implicite : tout est dans le lockfile.
2. Docker Tag — L’image est chargée puis taguée avec latest et le short SHA du commit pour la traçabilité.
3. Trivy Scan — Scan de sécurité automatique. Si des CVE critiques non acceptées sont détectées, le build est bloqué (exit code 1). Seules les CVE documentées dans .trivyignore sont autorisées.
4. Push — L’image validée est poussée vers Artifact Registry, prête à être déployée sur Cloud Run.
Le tout s’exécute via un simple make build côté développeur — Cloud Build s’occupe du reste.
La forge : L’Agent IA en action¶
Une workstation à la demande prend tout son sens lorsque le travail préparatoire a été mâché par une intelligence artificielle. Pour faire le pont entre une “Issue” métier (le besoin) et l’environnement Cloud Run (la validation), nous avons besoin d’une forge automatisée.
Plutôt que d’exécuter un agent IA en local sur la machine du développeur, nous déléguons cette tâche à la CI/CD (ici GitLab CI), via un composant réutilisable (CI/CD Catalog). Voici comment fonctionne ce pipeline asynchrone :
- Déclenchement (Trigger) : Ce job CI est conçu pour scruter les issues portant un label spécifique (ex:
agent::run). Il peut être déclenché manuellement par un développeur (via l’interface GitLab) ou planifié de manière régulière via un CRON job (Scheduled Pipeline) qui va parcourir la liste d’attente de façon autonome (par exemple, toutes les nuits). - Exécution du Gemini CLI : Le job CI instancie un environnement léger contenant un outil en ligne de commande (
gemini-cli) connecté à l’API Google Gemini. Ce CLI dispose d’outils (Function Calling / Tools) lui permettant de lire l’arborescence du projet, examiner le code existant et écrire de nouveaux fichiers. - Pre-coding de la feature : L’agent IA analyse la demande contenue dans le ticket. Il crée une nouvelle branche depuis
main, échafaude le code (scaffolding), écrit les tests de base et implémente la fonctionnalité demandée. - Injection de l’environnement (
devenv.nix) : C’est ici que la magie opère. L’IA sait de quels outils elle a besoin pour la feature (une nouvelle base Redis, l’ajout d’un compilateur Rust, un package Python spécifique, etc.). Elle va générer ou mettre à jour statiquement le fichierdevenv.nixà la racine du projet. - Merge Request et Hand-off : Le code généré est poussé sur GitLab et une Merge Request est automatiquement ouverte. Le développeur reçoit une notification : le terrain est préparé.
Le passage de relais :
Lorsque le développeur humain clique sur le lien pour démarrer sa Workstation Nix (Cloud Run), il bascule directement sur la branche de l’agent. La Workstation détecte automatiquement le fichier .vscode/extensions.json généré par l’IA et installe silencieusement les extensions recommandées en arrière-plan pendant le démarrage. Grâce au fichier devenv.nix fraîchement injecté, il lui suffit de taper devenv shell dans le terminal. Instantanément, toutes les dépendances requises par la nouvelle feature sont téléchargées et configurées via Nix, de manière parfaitement isolée et reproductible.
Le développeur n’a plus qu’à relire le code généré par l’IA, l’exécuter dans l’environnement préparé pour lui, ajuster les détails métier complexes et valider la Merge Request. Le cycle est bouclé.
Je ne vais pas détailler toute l’intégration de l’IA dans le projet, ce billet se concentrant plutôt sur l’idée de Workstation dans Cloud Run. Cependant, voici quelques indications sur le workflow que j’imagine.
Exemple d’intégration dans .gitlab-ci.yml :
Pour activer ce workflow dans n’importe quel projet, il suffit d’inclure le composant d’agent IA depuis le catalogue CI/CD GitLab :
include:
- component: {{CI_SERVER_HOST}}/mon-orga/catalog/gemini-agent@1.0.0
inputs:
trigger_label: "agent::run"
gemini_model: "gemini-2.5-pro"
Ce simple composant suffit à transformer votre GitLab CI en une véritable équipe de développement asynchrone, prête à préparer le terrain pour vos Workstations Nix.
Sous le capot : Le System Prompt de l’Agent
Pour que cet agent soit réellement autonome, voici un exemple de prompt système. Il définit clairement le rôle de l’agent, le concept de “Grove”, et insiste fortement sur la reproductibilité.
Voir le System Prompt de l'Agent Gemini
Tu es un Agent IA de Développement Autonome intégré dans une pipeline GitLab CI/CD.
Ton rôle est de préparer le terrain pour les développeurs humains en pré-codant des fonctionnalités et en provisionnant des environnements de développement (Workstations) entièrement prêts à l'emploi.
Voici ta mission. Tu dois exécuter ces étapes de manière séquentielle et autonome :
1. RECHERCHE DES ISSUES :
- Utilise l'API GitLab pour lister toutes les issues ouvertes du dépôt courant portant le label "{{trigger_label}}".
- Si aucune issue n'est trouvée, termine ton exécution avec succès.
2. POUR CHAQUE ISSUE TROUVÉE, exécute le workflow suivant :
A. ANALYSE ET PRÉPARATION :
- Lis attentivement la description de l'issue pour comprendre le besoin technique.
- Crée une nouvelle branche Git au nom explicite (ex: `feature/issue-<ID>-<nom-court>`).
B. CRÉATION DU GROVE (ESPACE DE TRAVAIL) :
- Provisionne un nouvel espace persistant (un "Grove") sur Google Cloud Storage (GCS) dédié à cette issue.
- Initialise ce grove en y clonant le code source de la branche nouvellement créée.
C. PRE-CODING & DEPENDANCES :
- Implémente la fonctionnalité demandée ou corrige le bug.
- Ajoute des tests unitaires basiques pour prouver le fonctionnement de ton code.
- CRITIQUE : Analyse les dépendances nécessaires à ton code (Node.js, Python, PostgreSQL, etc.). Tu DOIS générer ou mettre à jour le fichier `devenv.nix` à la racine du projet pour y déclarer ces dépendances, afin que l'environnement soit reproductible pour l'humain.
- CONFIGURATION IDE : Si le projet utilise Python, génère un fichier `.vscode/extensions.json` recommandant les extensions "ms-python.python" et "ms-python.vscode-pylance", ainsi qu'un fichier `.vscode/settings.json` configurant `python.defaultInterpreterPath` vers l'exécutable du virtualenv géré par devenv (c'est-à-dire `.devenv/state/venv/bin/python`).
- Commite tes changements et pousse la branche sur GitLab. Ouvre une Merge Request (WIP/Draft).
D. DEPLOIEMENT DE LA WORKSTATION :
- Utilise les scripts du dépôt (ex: `make deploy`) pour déployer une instance Cloud Run Workstation éphémère.
- Configure cette Workstation pour qu'elle monte le Grove GCS que tu as créé à l'étape B.
- Récupère l'URL d'accès HTTPS générée par Cloud Run et le mot de passe.
E. HAND-OFF (PASSAGE DE RELAIS) :
- Publie un commentaire détaillé sur l'Issue GitLab initiale contenant :
1. Le résumé de tes choix techniques.
2. Le lien vers la Merge Request.
3. Le lien d'accès direct vers la Workstation Cloud Run (avec la commande `devenv shell` suggérée).
4. Les instructions de connexion.
- Retire le label "{{trigger_label}}" et ajoute "ready-for-review".
RÈGLES STRICTES :
- Ne demande pas d'assistance humaine en cours de processus. Si tu rencontres une erreur, documente-la et passe à l'issue suivante.
- Le fichier `devenv.nix` est la source de vérité de l'infrastructure logicielle.
Pour démarrer¶
L’ensemble de ce socle d’infrastructure est open source. Trois commandes suffisent pour déployer votre propre environnement de révision “Scale-to-Zero” :
Une fois déployée, ouvrez l’URL affichée, entrez votre mot de passe, et vous voilà dans l’environnement de révision idéal — prêt à collaborer avec votre agent IA. Quand c’est fini, fermez simplement l’onglet. Zéro gaspillage, sécurité maximale.
🔗 Source du projet : gitlab.com/matgou/workstation-nix